
(1) 현실 세계의 데이터 모델링
데이터 사이언스의 프로세스와 전문가(Expert)에게 필요한 역량 모형을 이해합니다.
복잡한 현실을 목적에 맞게 추상화하는 데이터 모델링 방안을 학습합니다.
다양한 사례를 통해 분석의 목적과 실생활에서의 응용 방안 등 데이터 기반 의사결정의 전체 그림을 이해합니다.
(2) 데이터 수집과 분석을 위한 전처리
온라인 서베이 도구 및 엑셀의 크롤링 도구를 활용하여 분석 대상 기초 데이터를 확보하는 방법을 배웁니다.
엑셀 기능과 함수를 사용하여 수집한 데이터를 분석 목적에 맞게 원하는 형태로 가공하는 방법과 실무에서 많이 쓰는 유용한 기능을 익힘으로써 엑셀과 친해집니다.
(3) 현실적인 기업의 비즈니스 데이터 분석 실무
알고 있는 데이터를 사용하여 모르는 데이터를 추론하는 모집단 추정 원리와 표본 데이터의 신뢰도 확보 문제를 이해합니다. T검정, 카이제곱검정, 회귀분석을 적용하는 기준과 현실적인 활용법을 실습합니다.
다양한 비즈니스 분석 모델과 분석 알고리즘의 필요성을 이해하고, 실제 기업 사례에 적용하여 결론을 도출합니다.
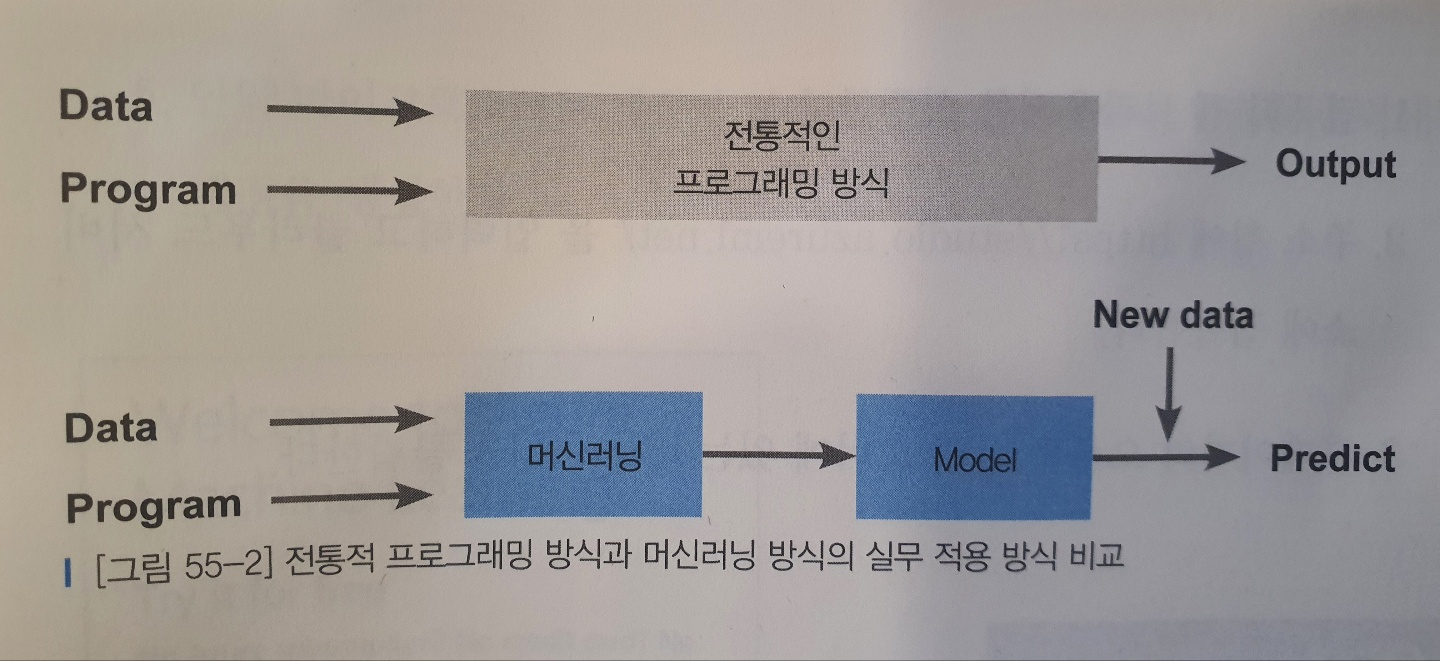
머신러닝의 원리와 실무 적용 방법을 이해합니다.
(4) 효과적인 분석 결과 공유를 위한 데이터 시각화
분석 모델에 최적화된 데이터 시각화 개념을 이해하고 적절한 시각화 기법을 선택할 수 있습니다.
엑셀 피벗테이블과 Power View를 활용하여 Interactive Dashboard를 설계하는 시각화 실무 역량을 확보합니다.
PART 1 메가트렌드와 데이터 분석
ㆍ데이터 분석의 목적은 '더 좋은 의사결정'입니다.
ㆍ오프라인 중심으로 생각하고 행동하던 방식을 디지털 경제에 알맞은 형식으로 바꿔 가는 일련의 과정을 디지털 전환 digital transformation 이라 한다. 새로운 디지털 경제 구조에 적합한 역량을 갖춰 나가는 조직적, 또는 개인적인 변화인 것이다.
ㆍ엑셀로 설명하므로 누구나 배우면 바로 활용할 수 있습니다. 분석 도구로 엑셀을 사용합니다. 데이터 분석이라면 R이나 Python을 떠올리지만, 고급 도구는 평범한 직장인에게 딱히 쓸모가 없습니다. 쉽게 손이 가는 간단한 도구로 배워야 실용적으로 쓸 수 있습니다
ㆍ데이터 사이언스 프로세스는 우리가 속한 현실 세계를 어떻게 데이터로 표현해낼 것인가에서부터 시작한다. 여기서 현실 세계를 데이터화 하는 일을 데이터 모델링 과정으로 표현할 수 있다. 데이터 모델링 이후 단계는 데이터 취합인데, 확보하려는 목표 데이터를 설정하고, 데이터 수집을 진행하는 단계이다. 주로 서베이 설문조사를 통해 데이터를 확보하거나 웹에 있는 데이터를 가져오는 등의 방법을 활용한다.

ㆍ한정된 표본으로 모집단의 데이터를 추측하는 방법, 이에 대한 해답을 연구하는 학문이 바로 통계학이다.
ㆍ데이터 사이언스 프로세스의 최종 단계는 의미 있는 통찰인 인사이트를 도출하고 실행에 옮기는 일이다. 이때, 도출한 인사이트를 집단 구성원끼리 쉽게 공유하고 이해하기 위해 시각화 보고서를 작성하며, 이 시각화 보고서를 토대로 더 나은 의사 결정을 내린다.
ㆍ데이터는 정보를 구성하는 가장 단위로, 문자 또는 숫자로 이루어진다.
ㆍ데이터 분석은 더 나은 의사 결정을 내리기 위해 진행한다. 데이터 분석시 항상 이 목적을 염두에 두고 질문하는 습관을 길러야 한다. 여기서 질문 던지기란 다른 말로 가설을 세우는 일이다.
ㆍ모델링에서 수집하는 모든 데이터는 의사 결정을 진행하기 위해서 문자 데이터 혹은 숫자 데이터로 만들어 내야 한다. 자료의 정보화란 의사 결정을 목표로 하여 질문을 생성하고, 답을 찾기 위해 숫자 및 문자 데이터를 확보하고 분류해서 인사이트를 도출하는 과정이다.
ㆍ목표로 하는 데이터는 과연 어떻게 확보할 수 있을까? 데이터 수집에는 직접 데이터를 만들어 내거나, 이미 세상에 존재하는 데이터를 수집하여 사용하는 두 가지 방법이 있다.
ㆍ데이터 분석의 단계는, 데이터를
수집하고,
저장하고,
가공하고,
분석하고,
시각화한다.
ㆍ파워쿼리는 다양한 유형의 데이터를 검색하고, 연결하고, 결합하여 분석이 편리한 형태로 가공하는 강력한 데이터 전처리 기능을 제공한다.
PART 2 현실 세계의 데이터 모델링
01 데이터 사이언스 프로세스란?
02 데이터란 무엇인가?
03 자료의 정보화
04 1차 자료와 설문 조사 방식(Survey)
05 설문 조사(Survey) 방식을 활용한 데이터 수집
06 크롤링을 위한 기본 환경 구성 이해: 파워쿼리
07 2차 자료와 크롤링
08 파워쿼리를 활용한 웹 크롤링 진행하기
ㆍ데이터 분석이란 '데이터를 요약하는 기술'로 표현할 수 있다. 인사이트 도출을 위해 데이터를 요약하는 것에서 데이터 분석이 시작되는데, 기술통계가 바로 데이터를 통계량이나 그래프로 요약하는 방법을 의미한다.
ㆍ전처리란 빈 데이터를 결측치로, 이상한 데이터를 이상치로 분류하고 확보한 전체 데이터에 발생하는 문제를 바로잡는 일을 가리킨다. 데이터 전처리 단계를 거친 깨끗한 데이터 셋을 마스터 데이터 셋이라고 부른다.
PART 3 데이터 분석과 통계 - 통계의 이해
01 기술통계
02 데이터와 통계량
03 분산과 표준편차
04 표본과 모집단의 관계
05 몬테카를로 실험 설계 및 실행
06 중심 극한 정리
07 중심 극한 정리와 Pilgrim Bank 표본 실험
08 Population Table을 활용한 표본 개수 의사결정
ㆍ통계량이란 전체 데이터에서 나타나는 특징을 숫자로 요약한 값이다.
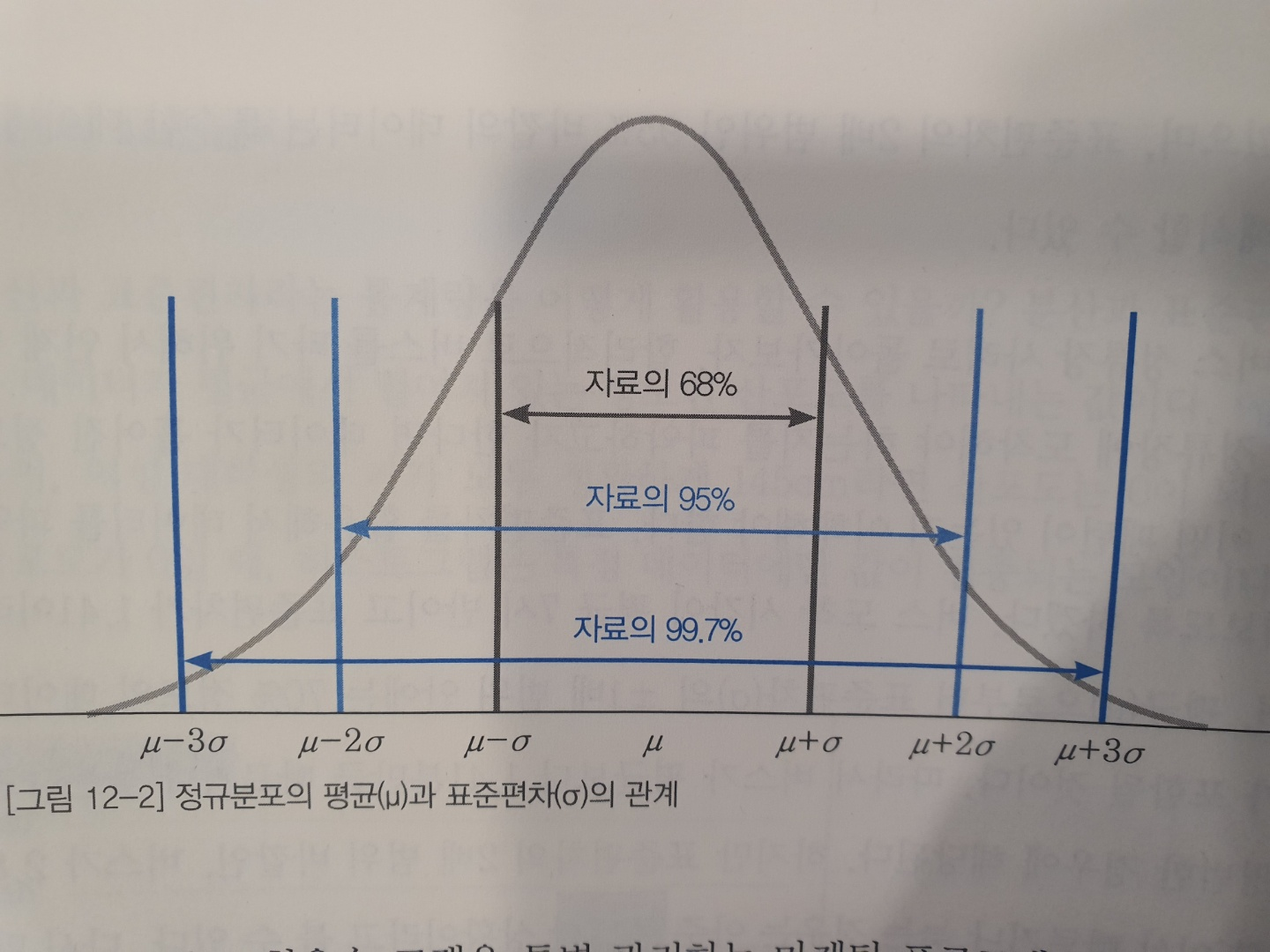
ㆍ분산과 표준편차는 데이터가 평균에서 떨어져 있는 정도인 산포도를 나타내는 값이다.
PART 4 데이터 분석과 통계 - 추론 통계
01 논리적 추론과 피어슨 추론
02 유의성 검정 원리
03 주요 유의 확률 계산 도구 소개
04 유의성 검정 도구 KESS 설치
05 목적에 맞는 유의성 검정
06 카이제곱검정이란?
07 카이제곱검정: 월마트(Walmart) 영수증
08 T검정이란?
09 T검정: 이메일 모금 실험
10 회귀분석이란?
11 회귀분석: 케냐 구호사업
ㆍ회귀분석은 숫자와 숫자로 이루어진 변수 사이에서 나타나는 경향성을 설명한다. 변수 사이에 있을 법한 관계를 바탕으로 세운 여러 가설을 회귀 모형이라고 한다. ex) 부모의 키가 극단적으로 크거나 작아도 자손의 키는 결국 평균으로 회귀한다.
ㆍ카이제곱검정은 문자와 문자 데이터, 즉 범주형 변수 간의 관련성을 검증하는 방법이다. 카이제곱검정의 창시자는 피어슨 통계의 칼 피어슨(Karl Pearson)이다. 이 검정 방법은 수집한 자료의 빈도가 이론상 기대 빈도와 통계적으로 다른지 판단하고자 할 때 사용하는 추론 통계 방식이다.
PART 5 데이터 전처리
01 데이터 전처리 입문
02 결측치 처리
03 데이터 클렌징
04 금액 단위 변경
05 텍스트 나누기 및 개체 삭제
06 데이터 타입 오류 사례
07 데이터 전처리 종합사례 01
08 데이터 전처리 종합사례 02
PART 6 데이터 분석 도구 활용
01 엑셀 데이터 관리 유형 이해: 테이블, 크로스탭, 템플릿
02 엑셀 데이터 관리 유형 이해하기
03 엑셀 Core 기능 표 등록 및 활용 방안
04 엑셀 Core 기능 이름 정의 및 활용 방안
05 엑셀 에러 처리와 VLOOKUP 활용 방안
06 혼합 참조 이해와 민감도 분석 적용 방안
07 소매점 판매 데이터를 활용한 비즈니스 분석 입문
08 주요 데이터 분석 도구 장단점 정리
PART 7 비즈니스 데이터 분석 실무
01 주요 KPI의 이해
02 BSC 프레임워크 기반 분석 목표 KPI 도출 전략
03 분석 대상 데이터 이해하기
04 분석 모델 기반 데이터 분석 입문
05 Key Metrics 도출하기
06 경향분석(Trend Analysis)
07 비교분석(Comparison Analysis)
08 순위분석(Ranking Analysis)
09 기여분석(Contribution Analysis)
10 빈도분석(Frequency Analysis)
11 차이분석(Variance Analysis)
12 파레토 분석(Pareto Analysis)
13 상관분석(Correlation Analysis)
14 Interactive Dashboard 구성
ㆍ비즈니스 분석 모델에는 경향분석, 비교분석, 순위분석, 기여분석, 빈도분석, 차이분석, 파레토 분석, 상관분석 등 매우 다양한 분석 모델이 존재한다. 확보한 데이터에서 목적에 알맞은 분석 모델을 적용하여 인사이트를 도출하고, 의미 있는 가설을 세워가는 방식으로 다양한 추가 분석을 진행할 수 있다.
ㆍ상관 분석은 두 변수에 대한 데이터를 비교하여 상호 관련 여부를 도출하는 분석 방법이다. 주로 ‘매출과 이익의 관련 여부 분석이나 ‘국가별 매출과 이익의 관련성 분석’과 같은 케이스에 활용한다. 이때 매출과 이익이 일정한 패턴으로 선형을 이루며 연관성이 있기를 많이 기대하지만, 고객이나 제품에 따라 기대와 다른 결과가 나오기도 한다. 이처럼 기대치와 다른 영역을 분석할 때에도 상관분석을 활용할 수 있으며, 주로 분산형 그래프 혹은 거품형 그래프로 시각화한다.
PART 8 머신러닝 입무
01 머신러닝이란?
02 베이즈 추론이란?
03 베이즈통계 입문: 빼빼로데이에 초콜릿을 건넨 그 남자의 진정성 추정하기
04 베이즈통계: 단지 문제 해결 방식
05 베이즈통계: 스팸메일 필터 구현하기
06 베이즈통계: 축차 합리성
ㆍ정보를 얻으면 확률이 바뀐다.
ㆍ확률 추측에는 언제나 방대한 정보를 사용한다. 그런데 매번 모든 정보를 일일일 총동원해서 추측해야 한다면 굉장히 번거롭고, 저장 용량도 많이 필요할 것이다. 반면 계산이 끝날 때마다 필요한 정보만 남겨 재사용하고, 나머지 정보를 삭제할 수 있다면 많은 에너지를 절약할 수 있다. 이것이 베이즈 추정의 힘이다.
PART 9 AZUREML을 활용한 머신러닝 실무
01 머신러닝과 AZUREML
02 Linear Regression을 활용한 적정 집값 예측하기
03 적용된 모델의 예측력 비교하기
04 Decision Tree를 활용한 신용평가 모형 개발하기
05 Logistic Regression을 활용한 직원 이탈 가능성 예측하기
PART 10 데이터 사이언스 정리
01 데이터 사이언스 프로세스 정리



